How to build a tool like Zapier using Lambda, SQS & DynamoDB

Introduction
Zapier is a no-code workflow automation tool that can be used to integrate apps and make them work together. I have been using Zapier for a bunch of my side projects and it was been pretty useful to hook up services like Stripe with Gmail. However, I recently started hitting their free tier limits and started exploring the possibility of building a simple Zapier alternative, mostly for fun.
The requirements that I came up with :
- Completely serverless: I don’t want to manage any infrastructure
- (almost) Free: It should cost close to $0 for my use-case which I will talk about below.
- Multi-step workflows: Currently, Zapier’s free tier only lets you perform one action for a particular trigger. I wanted the ability to perform multiple actions (for e.g. send an email and a slack message) for a particular trigger.
- Webhooks support: I’m a big fan of Zapier’s webhooks functionality and want to replicate that.
- Polling-based workflows: Ability to poll an API endpoint and take action if there is new data available
Overview
The following section will provide an overview of the system based on the requirements we came up with.
What is a workflow?
A workflow can be defined as a Trigger and a series of actions that are taken as a result of the Trigger. The trigger can be based on webhooks or polling.
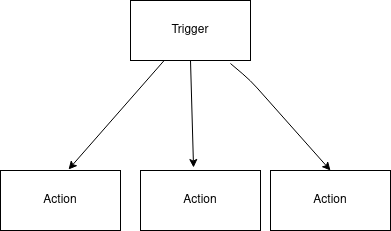
There are various ways to model a workflow. Some of the most common ones are:
- Using code: In a system like Airflow, a workflow (called a DAG) is defined in Python using Airflow specific abstractions.
- Using config files: A workflow engine like Argo, which is built on top of Kubernetes, uses YAML to define workflows.
To keep our system simple, we will define our workflows using JSON. JSON is natively supported in Python (my language of choice) along with many other programming languages.
What is a Trigger?
A trigger is the root node of a workflow. We will support two types of triggers in our system:
- Webhooks: The workflow will expose a webhook that can be used to initiate this particular workflow. The webhook will accept POST requests.
- Polling: The workflow will specify an API endpoint which will be polled at a regular interval. If new data is available, then specified actions will be run
What is an Action?
An action is performed as a result of a workflow being triggered. We will support two types of actions in our system:
- Email: Send an email with the data coming from the trigger
- Slack: Send a slack message with the data coming from the trigger.
Designing the system
In the following section, we will take a look at the various services we will be using to build the system based on our requirements.
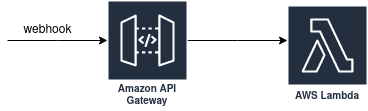
Creating Webhooks
Since one of the main requirements for the system is to be serverless, we will leverage API Gateway and Lambda to support webhooks. API Gateway will create a single endpoint that we can use to send webhooks and we will do the filtering in our Lambda function.
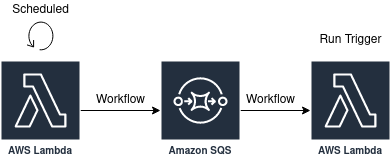
Supporting Polling-based Triggers
Polling triggers are slightly more involved. The system comprises of the following parts:
- A Lambda function scheduled at a regular frequency. This lambda function will go through all the workflows that are polling-based and put them in an SQS queue. The benefit of decoupling the scheduling of the workflow from the processing of the workflow is that we will be communicating with external services that could be unreliable. If there is a failure, we want to isolate it to a particular workflow.
- Lambda function which gets triggered whenever there is a new workflow has been enqueued. This function is responsible for executing the trigger i.e. querying the API endpoint and checking if there is any new data available.
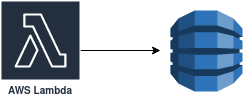
De-duplication
We only want to execute our actions for the polling-based workflows when there is new data. To support this, we will use a de-duplication identifier similar to Zapier. We will use DynamoDB to store the identifiers we have already processed for a particular workflow. Since our data model is pretty straightforward, DynamoDB is a good fit for us.
Performing Actions
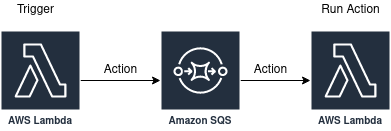
Since we want to support workflows where a single trigger could lead to multiple actions, we will use SQS to decouple the trigger from the action.
- Lambda function which processes the trigger and if there are any actions to run, enqueue them to SQS.
- Lambda function which runs the actions as a result of messages being enqueued to S3.
Some of the benefits of this architecture are:
- Actions are isolated from each other. If one action fails, other actions won’t be affected. We could even use a Dead-Letter queue to debug and process failed actions.
- Trigger and action are decoupled. Since there could be multiple actions that could take a variable amount of time, processing everything in a single Lambda function could lead to Lambda timeouts.
Cost
Now that we have a rough idea of how to build such a system, let’s look at what it will potentially cost us. I came up with a rough estimate of how this system would be used based on my current usage of Zapier:
- Run 5 workflows: 3 of them are webhooks based, the rest are polling-based. For simplicity, let’s assume each of these workflows have 2 actions.
- The webhooks based workflows are triggered roughly 10 times a day. Thus, the total number of webhooks-based workflow executions would be 30/day.
- The polling workflows would run once every 12 hours and they would check for any new data in the API endpoints.
Next, let’s look at the pricing of the various AWS services we are planning to use.
AWS Lambda
AWS Lambda has a pretty generous free tier which includes 1M free requests per month and 400,000 GB-seconds of compute time per month.
These are the Lambda functions that we currently have in the system:
- Webhooks: This function accepts any incoming webhooks and if a matching workflow exists, enqueues downstream tasks to SQS.
- Polling Trigger: There are two lambda functions to support polling triggers. The first one runs once every 12 hours and enqueues any poll-based workflows whereas the second function runs once for each poll-based workflow and checks if any new data is available.
- Actions: We run one Lambda function for every action in a workflow.
Based on our previous assumptions of usage, the number of Lambda requests we would have every month are:
- Webhooks: 30 requests / day * 2 actions / workflow = 60 / day = 1800 / month
- Polling: 2 requests / day + 2 workflows * 2 actions / workflow = 6 / day = 180 / month
For the sake of simplicity, we can assume that our Lambda functions on average run for 30 seconds (probably much lower than this) and they take 1024 MB of memory.
Using these assumptions, our total compute will be (1024 MB * 30s * 1880 request) / 1024 = 56400 GB-seconds per month. We are under the free tier limit on Lambda.
Cost for Lambda (using free tier): $0 / month

Cost for Lambda (assuming we aren’t eligible for the free tier): $0.20 + 56400 * $0.0000166667 = $ 1.14 / month
SQS
Similar to Lambda, SQS also has a pretty generous free tier. The first 1 million monthly requests are free. Every API action counts as a request.
A rough estimate of the number of requests we would make to SQS are:
- Webhooks: For every webhooks request we get, we would enqueue the actions for the workflow to SQS. Then, Lambda functions which execute the actions would dequeue these actions and run them.
- Polling-based: Every time a polling-based workflow is scheduled, we would first enqueue all the polling-based workflows into SQS. Then, a Lambda function would dequeue these workflows and then enqueue any actions in these workflows to a different SQS queue which would eventually get dequeued by the Lambda function which runs the actions.
Based on the description above, the number of SQS requests we would make are:
- Webhooks: 30 requests / day * 2 actions / workflow (enqueued) * 2 actions / workflow (dequeued) = 120 requests / day = 3600 requests / month
- Polling-based: 2 requests / day * 2 polling-based workflows (enqueued) * 2 polling-based workflows (dequeued) * 2 actions / workflow (enqueued) * 2 actions / workflow (dequeued) = 32 requests / day = 960 requests / month
Total number of requests to SQS in a month: ~5000 requests / month
Cost for SQS (regardless of tier): $0 / month
API Gateway
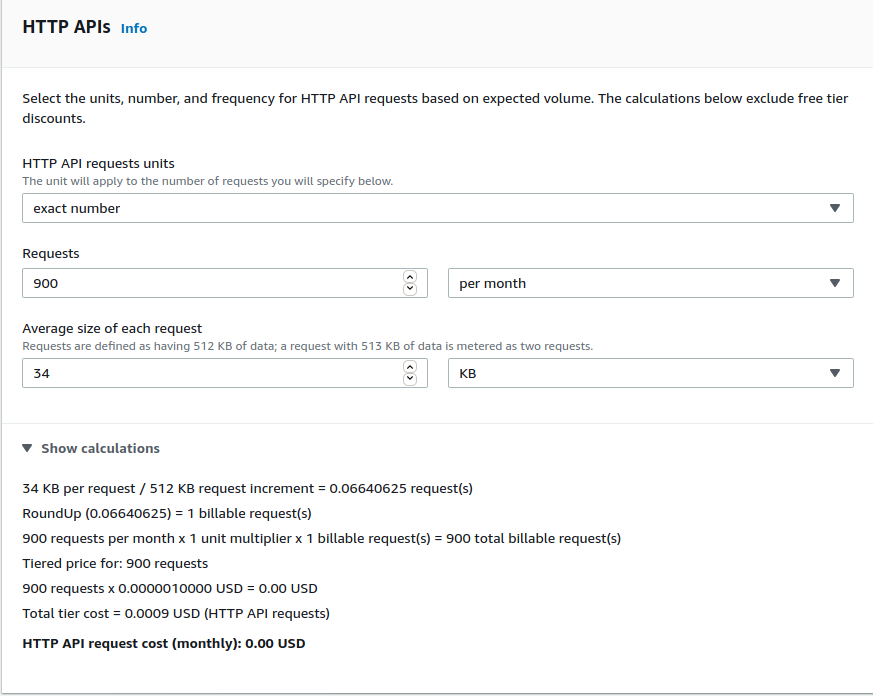
The API Gateway will only be used by our webhooks workflows. Based on our assumptions above, we will make roughly 900 requests/month to our API Gateway.
Cost for API Gateway: ~$0 / month
DynamoDB
DynamoDB has the most complicated pricing model out of all the services we are planning to use. More details about pricing is available here.
We will be using DynamoDB only for polling-based workflows to ensure we can deduplicate any data.
The schema for our table would look like this:
{
# primary_key
"workflow_id": {
"S": "my_workflow"
},
"processed_keys": {
"SS": {"1234", "1235"}
}
}
- Primary key would be the name of the particular workflow
- We would also store the set of processed unique identifiers for the data. For the sake of simplicity, we can assume these identifiers would be approximately 10 characters in length.
Based on our usage model, we expect to make the following requests to DynamoDB:
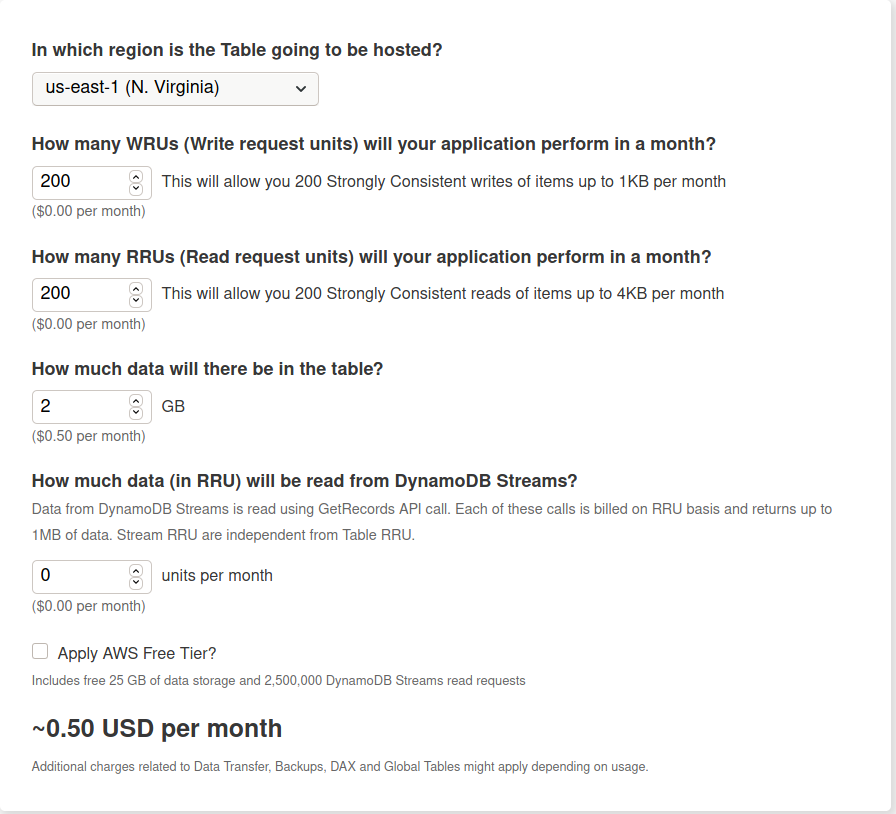
- Read requests: 2 polling workflows * 2 triggers / day * 1 read request = 4 requests/day or 120 requests/month
- Write requests: A Write request would only be made when there is new data available in the API. Let’s assume we will have new data every time the workflow is triggered: 4 requests/day or 120 requests/month.
I used this pricing calculator for DynamoDB and used conservative estimates that we calculated above.
Cost for Dynamo: ~0.50 / month
Total Cost
If we assume that we are within the limits of the free tier usage for Lambda and SQS, this system will cost us ~$0.50 / month.
If we include the cost for Lambda, our system will cost us ~$1.64 / month.
This meets our requirement of the system being cheap to run and manage. We can probably handle a lot more workflows before cost will be a meaningful issue for us.
Building the system
Now that we designed the system and also done a rough cost analysis and made sure that they adhere to our initial requirements, we can start writing some code to build the system.
Prerequisites
- Serverless framework: We will be using the Serverless Framework to create our application.
- virtualenv: Virtualenv is a tool to create isolated python environments. We will be using it to create an isolated environment for our application. Instructions for installation are available [here][install-virtualenv].
Getting Started
The source code for the project is available at this repository.
Project Setup
Create a new directory for the application
mkdir serverless-workflow-automation
cd serverless-workflow-automation
Setup a virtualenv for the application
virtualenv env
source env/bin/activate
Create requirements.txt with all the dependencies
boto3
Flask
pynamodb
boto3: We will use the boto library to interact with SQS.Flask: We will Flask to support our incoming webhooks.pynamodb: PynamoDB provides a Pythonic-interface to DynamoDB.
Install the dependencies
Run the following command in the shell to install all the dependencies.
pip install -r requirements.txt
Setup Serverless
Prerequisites
-
Setup serverless framework by following the instructions listed [here][serverless-instructions].
-
Run the following commands after installing the serverless framework.
npm init -f npm install --save-dev serverless-python-requirements
The serverless-python-requirements plugin automatically bundles dependencies from requirements.txt and makes them available to your Lambda function.
Create scaffolding
We will create a new folder called workflows which will store the application logic. api.py contains the logic to handle webhooks whereas email.py provides the logic to interact with SES to send emails.
mkdir app
touch workflows/__init__.py workflows/api.py app/email.py
We will also create a file called handler.py in the root directory. This file will contain the lambda functions to run actions and handle polling-based workflows.
touch handler.py
Adding Webhooks workflows
Webserver
We will use Flask to create a webserver which will expose a POST endpoint that will handle incoming webhooks
Let’s create a file named api.py under the workflows folder with the following contents:
import boto3
import json
import requests
from pathlib import Path
from flask import Flask, request
app = Flask(__name__)
FILE_DIR = Path(__file__).resolve().parent
SQS = boto3.resource("sqs")
ACTIONS_QUEUE = SQS.get_queue_by_name(QueueName="workflow-actions")
@app.route("/<path:path>", methods=["POST"])
def webhooks_trigger(path):
config_path = FILE_DIR / f"{path}.json"
if config_path.is_file():
run_workflow(path, request.json)
return "Success!"
return f"Workflow: {path} not found"
def run_workflow(name, workflow_data):
workflow_path = FILE_DIR / f"{name}.json"
with open(workflow_path) as f:
config = json.load(f)
actions = config["actions"]
for action in actions:
enqueue_action(action=action, step_data=workflow_data)
def enqueue_action(action, step_data):
message_data = {
"workflow_data": step_data,
"action": action,
}
ACTIONS_QUEUE.send_message(MessageBody=json.dumps(message_data))
Key Points
- We have a function called
webhooks_triggerwhich acts as a catch-all for incoming POST requests. This function checks if a workflow exists for this particular path and then runs the specified workflow. - The
run_workflowfunction parses the specified workflow and enqueues any actions to SQS. The enqueued message also contains any data sent to the webhook.
Actions
We currently support email via SES as a downstream action. The contents of email.py are:
import boto3
class EmailClient:
SENDER = "Workflow Update <[email protected]>"
# The email body for recipients with non-HTML email clients.
BODY_TEXT = "{email_text}"
# The HTML body of the email.
BODY_HTML = """<html>
<head></head>
<body>
<p>{email_text}</p>
<hr/>
</body>
</html>
"""
# The character encoding for the email.
CHARSET = "UTF-8"
def __init__(self):
self.client = boto3.client("ses")
def send(self, subject, recipient, email_data):
"""Send an email which contains AWS billing data"""
email_text = "\n".join(email_data)
email_html = "<br>".join(email_data)
response = self.client.send_email(
Destination={
"ToAddresses": [
recipient,
],
},
Message={
"Body": {
"Html": {
"Charset": self.CHARSET,
"Data": email_html
},
"Text": {
"Charset": self.CHARSET,
"Data": email_text,
},
},
"Subject": {
"Charset": self.CHARSET,
"Data": subject,
},
},
Source=self.SENDER,
)
The email functionality is pretty straightforward. We send an email to the specified recipient and include the data we want.
Running the Action
Now, we need to handle any action that might have been enqueued as a result of the workflow being triggered. Our handler.py file would look like the following:
import boto3
import json
import requests
from pathlib import Path
n
from workflows.email import EmailClient
def run_actions(event, context):
records = event["Records"]
for record in records:
message_data = json.loads(record["body"])
print(message_data)
action = message_data["action"]
workflow_data = message_data['workflow_data']
if action["type"] == "email":
run_email_action(action["action_data"], workflow_data)
return {
"statusCode": 200,
"headers": {
"Content-Type": "application/json",
},
"body": "success",
}
def run_email_action(action_data, workflow_data):
recipient = action_data["recipient"]
subject = action_data["subject"]
email_client = EmailClient()
email_client.send(
subject=subject,
recipient=recipient,
email_data=[f"{k}: {v}" for k, v in workflow_data.items()]
)
run_actions: This function is triggered whenever there is a message in the SQS queue responsible for storing actions. We iterate through the messages and for any message which has the typeemail, we run the email action.
Setting up the serverless project
Next, let’s setup our serverless project config and deploy this project to test it out. First, create the file serverless.yml in your root directory and copy the following content:
service: serverless-workflow-automation
plugins:
- serverless-python-requirements
- serverless-wsgi
package:
individually: true
excludeDevDependencies: true
custom:
wsgi:
app: workflows.api.app
pythonBin: python3
pythonRequirements:
slim: true
strip: false
slimPatternsAppendDefaults: true
slimPatterns:
- "**/*.egg-info*"
- "**/*.dist-info*"
dockerizePip: true
provider:
name: aws
runtime: python3.7
stage: dev
region: us-west-2
iamRoleStatements:
- Effect: "Allow"
Action:
- "sqs:SendMessage"
- "sqs:GetQueueUrl"
Resource: "arn:aws:sqs:us-west-2:YOUR-ACCOUNT-NUMBER:workflow-actions"
- Effect: Allow
Action:
- ses:SendEmail
functions:
api:
handler: wsgi_handler.handler
events:
- http: ANY /
- http: ANY {proxy+}
actions:
handler: handler.run_actions
events:
- sqs: arn:aws:sqs:us-west-2:YOUR-ACCOUNT-NUMBER:workflow-actions
Key points
- Our lambda function
run_actionsis specified to trigger via the SQS queue for our actions
Create a workflow
Let’s create a new webhooks based workflow named test-webhooks.json under the workflows folder.
{
"name": "test-webhooks",
"type": "webhook",
"actions": [
{
"type": "email",
"action_data": {
"subject": "Testing webhooks workflow",
"recipient": "[email protected]"
}
}
]
}
Deploy
To deploy our project, we will run the following command:
sls deploy
Once the deployment is successful, we should be able to see the endpoint exposed by our webhooks server.
endpoints:
ANY - https://some-random-identifier.execute-api.us-west-2.amazonaws.com/dev
ANY - https://some-random-identifier.execute-api.us-west-2.amazonaws.com/dev/{proxy+}
We will use this endpoint to make a curl request to trigger our workflow and check if we receive an email:
curl -X POST -H "Content-Type: application/json" -d '{"key": "value"}' https://some-random-identifier.execute-api.us-west-2.amazonaws.com/dev/test-webhooks
Success!%
This is the email we received as part of the workflow:
Polling-based Workflows
Now that our webhooks based workflow is working as expected, we will go ahead and set up our polling-based workflows.
DynamoDB model
We will define our DynamoDB table based on the schema we specified earlier in the article. Create a file called models.py under the workflows folder.
from pynamodb.models import Model
from pynamodb.attributes import (
UnicodeAttribute,
UnicodeSetAttribute,
)
from workflows.config import AWS_REGION, TABLE_NAME
class PollTrigger(Model):
class Meta:
table_name = TABLE_NAME
region = AWS_REGION
trigger_name = UnicodeAttribute(hash_key=True)
processed_keys = UnicodeSetAttribute()
def create_or_get_trigger(trigger_name):
try:
return PollTrigger.get(trigger_name)
except PollTrigger.DoesNotExist:
return PollTrigger(
trigger_name=trigger_name,
processed_keys=set()
)
Lambda function
Next, we will update handler.py to include additional lambda functions to handle polling-based workflows. The new functions would look like:
from workflows.models import create_or_get_trigger
FILE_DIR = Path(__file__).resolve().parent / "workflows"
SQS = boto3.resource("sqs")
TRIGGERS_QUEUE = SQS.get_queue_by_name(QueueName="workflow-triggers")
def get_workflows():
return [
ls.name.split(ls.suffix)[0]
for ls in FILE_DIR.iterdir()
if ls.is_file() and ls.suffix == ".json"
]
def check_poll_trigger(event, context):
workflows = get_workflows()
for workflow in workflows:
config_path = FILE_DIR / f"{workflow}.json"
with open(config_path) as f:
config = json.load(f)
if config["type"] == "poll":
message_body = {"name": workflow}
TRIGGERS_QUEUE.send_message(MessageBody=json.dumps(config))
return "Success!"
def _get_request_data(url, auth, data_key=None):
auth_header = (
auth["user"], auth["password"]
)
response = requests.get(url, auth=auth_header).json()
if data_key:
response = response[data_key]
return response
def run_poll_trigger(event, context):
records = event["Records"]
for record in records:
workflow = json.loads(record["body"])
data_key = workflow.get("data_key")
results = _get_request_data(
url=workflow["poll_url"],
auth=workflow["auth"],
data_key=data_key,
)
trigger_obj = create_or_get_trigger(workflow["name"])
if trigger_obj.processed_keys:
processed_keys = trigger_obj.processed_keys
else:
processed_keys = set()
dedupe_key = workflow["dedupe_key"]
for result in results:
if result[dedupe_key] not in processed_keys:
actions = workflow["actions"]
for action in actions:
enqueue_action(action=action, step_data=result)
processed_keys.add(result[dedupe_key])
trigger_obj.processed_keys = processed_keys
trigger_obj.save()
return {
"statusCode": 200,
"headers": {
"Content-Type": "application/json",
},
"body": "success",
}
Key Points
check_poll_trigger: Iterates through all the workflows and enqueues any workflow with the typepollto a new SQS queue specifically for triggers.run_poll_trigger: Runs a particular workflow and checks if there is any new data. If there is new data, the actions specified in the workflow are enqueued and run as specified previously.
Updating Serverless Config
Next, we will update our serverless config to include permissions for DynamoDB as well setting up the new lambda functions to handle poll-based workflows.
service: serverless-workflow-automation
plugins:
- serverless-python-requirements
- serverless-wsgi
package:
individually: true
excludeDevDependencies: true
custom:
wsgi:
app: workflows.api.app
pythonBin: python3
pythonRequirements:
slim: true
strip: false
slimPatternsAppendDefaults: true
slimPatterns:
- "**/*.egg-info*"
- "**/*.dist-info*"
dockerizePip: true
provider:
name: aws
runtime: python3.7
stage: dev
region: us-west-2
iamRoleStatements:
- Effect: "Allow"
Action:
- "sqs:SendMessage"
- "sqs:GetQueueUrl"
Resource: "arn:aws:sqs:us-west-2:YOUR-ACCOUNT-NUMBER:workflow-actions"
- Effect: "Allow"
Action:
- "sqs:SendMessage"
- "sqs:GetQueueUrl"
Resource: "arn:aws:sqs:us-west-2:YOUR-ACCOUNT-NUMBER:workflow-triggers"
- Effect: Allow
Action:
- ses:SendEmail
Resource:
- "*"
- Effect: Allow
Action:
- dynamodb:Query
- dynamodb:Scan
- dynamodb:GetItem
- dynamodb:PutItem
- dynamodb:UpdateItem
- dynamodb:DeleteItem
- dynamodb:DescribeTable
Resource:
- "arn:aws:dynamodb:${opt:region, self:provider.region}:*:table/${self:provider.environment.DYNAMODB_TABLE_NAME}"
functions:
api:
handler: wsgi_handler.handler
events:
- http: ANY /
- http: ANY {proxy+}
actions:
handler: handler.run_actions
events:
- sqs: arn:aws:sqs:us-west-2:YOUR-ACCOUNT-NUMBER:workflow-actions
check_poll_trigger:
handler: handler.check_poll_trigger
events:
- schedule: rate(1 day)
run_poll_trigger:
handler: handler.run_poll_trigger
reservedConcurrency: 1
events:
- sqs: arn:aws:sqs:us-west-2:YOUR-ACCOUNT-NUMBER:workflow-triggers
timeout: 30
resources:
Resources:
SlackTeamDynamoDbTable:
Type: 'AWS::DynamoDB::Table'
DeletionPolicy: Retain
Properties:
AttributeDefinitions:
- AttributeName: trigger_name
AttributeType: S
KeySchema:
- AttributeName: trigger_name
KeyType: HASH
ProvisionedThroughput:
ReadCapacityUnits: 1
WriteCapacityUnits: 1
SSESpecification:
SSEEnabled: true
TableName: ${self:provider.environment.DYNAMODB_TABLE_NAME}
Creating a poll-based workflow
We will create a polling-based workflow to retrieve new Covid-19 data using this api. This workflow will send us an email whenever new data is available.
{
"name": "covid-cases",
"type": "poll",
"poll_url": "https://api.covidtracking.com/v1/us/daily.json",
"dedupe_key": "hash",
"actions": [
{
"type": "email",
"action_data": {
"subject": "New covid data",
"recipient": "[email protected]"
}
}
]
}
Testing the new worfklow
Let’s deploy our changes.
sls deploy
When the Lambda function gets scheduled for the first time, we will receive an email with the entire contents of the API. For every subsequent run, we will receive an email only when there is new data.
Conclusion
Services like Lambda, SQS, & DynamoDB have made it pretty easy to build event-driven tools and this ended up being a pretty fun experiment for me. I have been using this new tool for the last couple of months to replace my Zapier usage and I haven’t run into any issues so far. The system itself is pretty straightforward and I have a few more ideas to extend it.